save-win10-spotlight

保存win10 spotlight 壁纸到D盘下!

1 将下面文本保存为win10_spotlight.bat(直接下载)
|
|
2 双击执行, 执行后前往D:\spotlight\查看
保存win10 spotlight 壁纸到D盘下!
1 将下面文本保存为win10_spotlight.bat(直接下载)
|
|
2 双击执行, 执行后前往D:\spotlight\查看
先看一个DNN, CNN, RNN的比较
| 深度 | 输入 | 参数 | 输出 | |
|---|---|---|---|---|
| DNN | 神经元堆叠层数 | 向量 | 连接 | 向量 |
| RNN | 序列长度 | 向量 | 连接 | 向量 |
| CNN | 一组操作(卷积, 池化) | 特征图 | 连接, 卷积核 | 特征图 |
Q:CNN中原图和卷积生成的特征图的位置是对应的吗?
转至: [Link]
CNN一个牛逼的地方就在于通过感受野和权值共享减少了神经网络需要训练的参数的个数。总之,卷积网络的核心思想是将:局部感受野、权值共享(或者权值复制)以及时间或空间亚采样这三种结构思想结合起来获得了某种程度的位移、尺度、形变不变性。
在GAN中, Adversarial Model的功能是判别样本是否来自于Generative Model.
而Generative Model的目标是最大化的混淆Adversarial Model.
在迁移学习中, 领域判别损失如下:
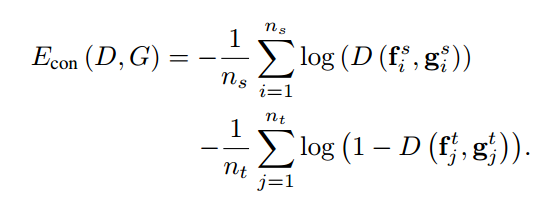
咋一看还看不懂了, 交叉熵损失也就是logloss不是这个样子的吗:
$$ H(x)\ =\ -\sum_{i}p_{i}\log q_{i}\ =\ -y\log{\hat{y}}-(1-y)\log(1-{\hat{y}}) $$ 其实也是啊, 可以从两个角度进行解释:
本科考研的时候, 我可能看上去比别人更努力一些. 为什么? 因为我知道我基础并不好, 所以我需要更多的努力. 俗话说, 笨鸟先飞, 我深深的铭记这句话. 每当他人问我为什么这么努力时, 我会说因为底子差, 比较笨, 所以需要更多努力, 笨鸟先飞嘛.
关于迁移学习, 领域适应, 对抗学习的论文, 代码汇总
https://xiaosean.github.io/posts/
台湾一名学生的主页, 主要包含一些阅读笔记, 包含的领域有领域适应, 生成对抗网络等.
tutorial 地址: pytorch: Training a Classifier.
当使用新的数据集进行测试时, 出现的问题及解决的方法.
error:
|
|
location:
|
|
solution:
|
|
error:
|
|
location:
|
|
solution:
|
|

https://www.nvidia.cn/object/what-is-gpu-computing-cn.html
理解 GPU 和 CPU 之间区别的一种简单方式是比较它们如何处理任务。CPU 由专为顺序串行处理而优化的几个核心组成,而 GPU 则拥有一个由数以千计的更小、更高效的核心(专为同时处理多重任务而设计)组成的大规模并行计算架构。
传说BERT牛皮得不行, 好奇看了看.
里面用到了Transformer Block, 这是什么结构? 其实也就是Attention as all you need的Transformer.
之前有了解过ImageNet有过巨大的标记成本, 找了些资料看了看, 这篇文章的信息量还是非常巨大的, 无论是从人工智能的技术角度, 还是社会角度, 都有所涉及.
